Retrieval Augmented Generation (RAG) represents a cutting-edge approach in the field of artificial intelligence, specifically in natural language processing. RAG enhances the capabilities of traditional language models by integrating retrieval mechanisms that fetch relevant external information to supplement the model’s responses. This blend of retrieval and generation processes significantly improves the contextual relevance and accuracy of the outputs.
Importance and Relevance of RAG
In a world where data is constantly evolving, ensuring that AI models can access and utilize the most current information is crucial. RAG addresses this need by enabling models to pull in fresh and relevant data from various sources, thereby providing more accurate and up-to-date responses.
Background of Retrieval Augmented Generation
Origins and Development
RAG emerged from the necessity to overcome the limitations of traditional language models, which often rely solely on static training data. These models can produce inaccurate or outdated responses due to their inability to access real-time information. The development of RAG integrates the strengths of information retrieval with generative models, allowing for a more dynamic and responsive AI.
Evolution from Traditional Generation Models
Traditional text generation models like GPT-3 have shown impressive capabilities but often struggle with providing accurate context when the information is outside their training data. RAG enhances these models by retrieving relevant information before generating a response, thus bridging the gap between static knowledge and real-time data needs.
Core Concepts
How RAG Works
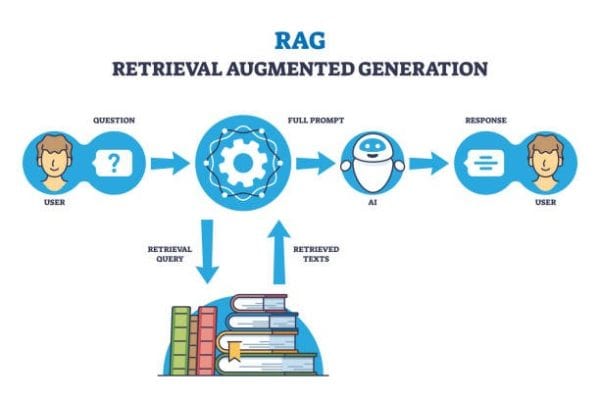
RAG operates by combining two main components: retrieval and generation. The process begins when a user submits a query to a RAG application. The application performs a similarity search against a vector database, identifying relevant document chunks to pass to the language model (LLM). The LLM then uses both the user query and the retrieved data to generate a more contextually accurate response.
The Retrieval Mechanism
Data retrieval in RAG involves scanning various sources to find the most relevant information. This can include file systems, external APIs, knowledge bases, SQL databases, and vector databases. The retrieval mechanism ensures that the model has access to up-to-date and pertinent information.
| Source Type | Retrieval Method | Examples |
| File Systems | File scanning | Internal documents, PDFs |
| APIs | API calls | External data services, weather APIs |
| Knowledge Bases | Full-text search | Internal wikis, FAQ databases |
| SQL Databases | SQL queries | Customer records, transaction histories |
| Vector Databases | Similarity search | Contextual embeddings, semantic search results |
The Generation Mechanism
The generation mechanism uses the retrieved data to enhance the model’s responses. By incorporating relevant chunks into the prompt, the model can generate answers that are both accurate and contextually appropriate, reducing the likelihood of hallucinations and misinformation.
Applications of RAG
Real-world Use Cases
RAG’s ability to merge real-time data retrieval with generative capabilities makes it valuable across various industries. Using tools like Vectorize you can already build pipelines for customer service bots accessing the latest product information to academic research assistants pulling in the most recent studies, RAG can significantly enhance the functionality and reliability of AI applications.
| Industry | Application | Benefits |
| Customer Service | Automated support | Accurate, up-to-date responses |
| Healthcare | Medical research assistance | Access to the latest medical studies |
| Finance | Financial advisory bots | Real-time market data and analysis |
| Education | Academic research assistants | Current and relevant educational resources |
| E-commerce | Personalized shopping assistants | Up-to-date product information and availability |
Benefits of RAG
Advantages over Traditional Methods
RAG offers several benefits that address the limitations of models:
- Prevents Hallucinations: By retrieving relevant information, RAG reduces the chances of generating incorrect or fictional responses.
- Cites Sources: RAG can provide references for the information it uses, enhancing the transparency and reliability of AI-generated content.
- Expands Use Cases: With access to a wide range of external information, RAG can handle diverse and complex queries.
- Easy Maintenance: Regularly updated data sources ensure the model remains accurate over time.
- Flexibility: Adaptable to various queries and knowledge domains.
- Improved Relevance: More precise and detailed responses due to a vast information base.
- Up-to-date Context: Ensures the latest information is always available for generating responses.
Challenges and Limitations
Current Obstacles
Despite its advantages, RAG faces several challenges:
- Data Quality: The accuracy of RAG’s responses depends on the quality and timeliness of the data in its knowledge base.
- Complexity in Implementation: Selecting the right extraction and embedding models can be challenging and may impact the performance and usability.
- Privacy Concerns: Introducing a vector database can lead to issues related to the proliferation of private data.
Dependence on Data Quality
The reliability of RAG’s outputs is heavily influenced by the quality of the data it retrieves. Poor data quality can lead to inaccurate responses, underscoring the importance of maintaining robust and current data sources.
Future Directions
Ongoing Research and Development
As RAG technology evolves, ongoing research focuses on improving retrieval mechanisms, RAG pipelines, enhancing integration with diverse data sources, and refining the generation processes. Future developments aim to make RAG even more efficient, accurate, and versatile, potentially expanding its application across more industries and use cases.
Emerging Trends
New trends in RAG technology include the integration of more sophisticated retrieval algorithms, enhanced natural language understanding capabilities, and greater emphasis on ethical considerations in data usage and privacy.
Summary of Key Points
- Prevents Hallucinations: Enhances accuracy by retrieving relevant data.
- Cites Sources: Improves transparency and credibility of AI responses.
- Expands Use Cases: Handles diverse and complex queries effectively.
- Easy Maintenance: Keeps models accurate with up-to-date information.
- Flexibility: Adapts to various queries and knowledge domains.
- Improved Relevance: Provides precise and detailed responses.
- Up-to-date Context: Ensures the latest information is always available.
RAG represents a significant advancement in AI technology, combining the strengths of retrieval and generation to deliver more accurate and relevant responses. By addressing the limitations of traditional language models, RAG opens new possibilities for the application of AI across various fields.


